Class- X_DBMS Unit 1: Introduction to Database System Architecture
What is Data?
Data is a
singular form of "Datum" is a collection of facts and figure, such as
numbers, words, measurements, observations or even just descriptions of things.
Data can be collected in many ways. The simplest way is direct observation.
Example: you
want to find how many cars pass by a certain point on a road in a 10-minute
interval.
So: stand at
that point on the road, and count the cars that pass by in that interval.
We collect data by
doing a Survey.
There are two
types of Data
Qualitative:
Qualitative
data is descriptive information (it describes something)
Quantitative:
Quantitative
data, is numerical information (numbers).

Quantitative
data can also be Discrete or Continuous:
Discrete
data can only take certain values (like whole numbers)
Continuous
data can take any value (within a range)
Discrete
data is counted, Continuous data is measured
Qualitative:
He is brown and
black
He has long hair
He has lots of
energy
Quantitative:
Discrete:
He has 4 legs
He has 2
brothers
Continuous:
He weighs 25.5
kg
He is 565 mm
tall
To help you
remember think "Quantitative is about Quantity"
Qualitative:
Your friends'
favorite holiday destination
The most common
given names in your town
How people
describe the smell of a new perfume
Quantitative:
Height
(Continuous)
Weight
(Continuous)
Petals on a
flower (Discrete)
Customers in a
shop (Discrete)
Information:
When data are processed, organized, structured or
presented in a given context so as to make them useful, they are called
Information. Information is data that has been processed in
such a way as to be meaningful to the person who receives it. it is any thing
that is communicated. So we can say, Information
is a processed form of data which gives meaningful information about an entity
( Person, Place or Thing).
Information is needed to:
• To gain
knowledge about the surroundings, and whatever is happening in the society and
universe.
• To keep
the system up to date.
• To know
about the rules and regulations and bye laws of society, local government,
provincial and central government, associations, clients etc. as ignorance is
no bliss.
• Based on
above three, to arrive at a particular decision for planning current and
prospective actions in process of forming, running and protecting a process or
system
Knowledge
Human mind
purposefully organized the information and evaluate it to produce knowledge. In
other words the ability of the person recalls or uses his information and
experience is known as knowledge. For example, "386" is data,
"your marks are 386" is information, and "It is result of your
hard work" is knowledge.
Knowledge is of two types:
• Facts based or Information based Knowledge:
The
knowledge gained from fundamentals and through experiments. The knowledge is
derived from the information contained in fundamental science derived from
experiments, rules, regulations commonly agreed by experts.
• Heuristic Knowledge:
It is knowledge
of good practice, experience and good judgment like hypothesis. It is the
knowledge underlying "expertise", rules of thumb, rules of good
guessing, that usually achieves desired results but do not guarantee them.
Today
Knowledge Management plays a significant role in the development of an
organization.
Differences Between Data and Information
Data
|
Information
|
1.
Data
is raw fact and figures.
Eg.
55 is data
|
1.
Information
is processed form of data.
Eg.
When 55 is stored in row column form as shown below is information
Age
55
|
2.
Data
is not significant to a business and of itself.
|
2.
Information
is significant to a business and of itself. For example 55 is insignificant
for business but Age 55 is significant for a business like music.
|
3.
Data
are atomic level piece of information.
|
3.
Information
is a collection of data. For example age and 55 collected together to form
information.
|
4.
Data
does not help in decision making.
|
4.
As
explained above information helps in decision making.
|
5.
for
example in the health care industries, much activity surrounds data
collection. Nurses collect data everyday and sometimes hourly. Examples of
data include vital signs. Weight and relevant assessment parameters.
|
5.
Information,
however, provides answers to questions that guide clinicians to change their
practices. for example, the trending of vital signs over time provides a
pattern that may lead to certain clinical decisions.
|
Database:
The organized collection of stored
information that can be shared and used for multiple purposes is known as a
database. A database document is just a collection
of information stored in computerized form. Computer databases
can be highly structured, storing the same kind of information about each item
in the database in well-defined compartments. A specific set of fields and
records organized in a specific order, including the information they contain,
is called a table. In fact, tables are often displayed on the screen with each
item, or record, in a row, and each field as a column.
Structured databases can be either flat
file databases or relational databases. In a flat file database, you can work
with only one data table-one set of fields-at a time. In a relational database,
you can use multiple tables (multiple database documents) at once. Flat file
databases are much easier to understand and use, but relational databases are
much more efficient for many things you commonly do with data, especially in
businesses.
A database can also be simply a free-form
collection of information, without any particular structure. In this case, the
analogy would be to a pile of notes you've written on whatever paper was handy
at the time the information on each piece of paper doesn't have to be organized
in the same way.
The term database can also refer to the
software package itself that you use to create the database. More often, the
software is called a "database program" ("database
application" is more specific) or a "database management system"
(DBMS).
A database application is one of the most
useful tools on the computer, and is actually an incredible amount of fun.
What
is DBMS?
DBMS A database management system is the
software system that allows users to define, create and maintain a database and
provides controlled access to the data.
A Database Management System (DBMS) is
basically a collection of programs that enables users to store, modify, and
extract information from a database as per the requirements. DBMS is
an intermediate layer between programs and the data. Programs access the DBMS,
which then accesses the data. There are different types of DBMS ranging from
small systems that run on personal computers to huge systems that run on
mainframes. The following are main examples of database applications:
• Computerized library systems
• Automated teller machines
• Flight reservation systems
• Computerized parts inventory systems
A database management system is a piece
of software that provides services for accessing a database, while maintaining
all the required features of the data. Commercially available Database
management systems in the market are dbase, FoxPro, IMS and Oracle, MySQL, SQL
Servers and DB2 etc.
These systems allow users to create
update, and extract information from their databases.
Compared to a manual filing system, the
biggest advantages to a computerized database system are speed, accuracy, and'
accessibility.
Components of the Database System Environment
There are five major components in the database system environment
and their interrelationship are.
• Hardware
• Software
• Data
• Users
• Procedures

1.Hardware:
The hardware is the actual computer system used for keeping and accessing
the database. Conventional DBMS hardware consists of secondary storage devices,
usually hard disks, on which the database physically resides, together with the
associated Input-Output devices, device controllers and· so forth. Databases
run on a' range of machines, from Microcomputers to large mainframes. Other
hardware issues for a DBMS includes database machines, which is hardware
designed specifically to support a database system.
2.
Software:
The software is the actual
DBMS. Between the physical database itself (i.e. the data as actually stored)
and the users of the system is a layer of software, usually called the Database
Management System or DBMS. All requests from users for access to the database
are handled by the DBMS. One general function provided by the DBMS is thus the
shielding of database users from complex hardware-level detail.
The DBMS allows the users to
communicate with the database. In a sense, it is the mediator between the
database and the users. The DBMS controls the access and helps to maintain the
consistency of the data. Utilities are usually included as part of the DBMS.
Some of the most common utilities are report writers and application
development.

3.
Data :
It is the most important
component of DBMS environment from the end users point of view. As shown in
observes that data acts as a bridge between the machine components and the user
components. The database contains the operational data and the meta-data, the
'data about data'.
The database should contain
all the data needed by the organization. One of the major features of databases
is that the actual data are separated from the programs that use the data. A
database should always be designed, built and populated for a particular
audience and for a specific purpose.
4. Users :
There are a number of users
who can access or retrieve data on demand using the applications and interfaces
provided by the DBMS. Each type of user needs different software capabilities.
The users of a database system can be classified in the following groups,
depending on their degrees of expertise or the mode of their interactions with
the DBMS. The users can be:
• Naive Users
• Online Users
• Application Programmers
• Sophisticated Users
• Data Base Administrator
(DBA)
Naive
Users:
Naive Users are those users
who need not be aware of the presence of the database system or any other
system supporting their usage. Naive users are end users of the database who
work through a menu driven application program, where the type and range of
response is always indicated to the user.
A user of an Automatic Teller
Machine (ATM) falls in this category. The user is instructed through each step
of a transaction. He or she then responds by pressing a coded key or entering a
numeric value. The operations that can be performed by valve users are very
limited and affect only a precise portion of the database. For example, in the
case of the user of the Automatic Teller Machine, user's action affects only
one or more of his/her own accounts.
Online
Users :
Online users are those who
may communicate with the database directly via an online terminal or indirectly
via a user interface and application program. These users are aware of the
presence of the database system and may have acquired a certain amount of
expertise with in the limited interaction permitted with a database.
Sophisticated
Users :
Such users interact with the
system without ,writing programs.
Instead, they form their
requests in database query language. Each such query is submitted to a very
processor whose function is to breakdown DML statement into instructions that
the storage manager understands.
Specialized
Users :
Such users are those ,who
write specialized database application that do not fit into the fractional
data-processing framework. For example: Computer-aided design systems,
knowledge base and expert system, systems that store data with complex data types (for example, graphics data
and audio data).
Application
Programmers :
Professional programmers are
those who are responsible for developing application programs or user
interface. The application programs could be written using general purpose
programming language or the commands available to manipulate a database.
Database
Administrator:
The database administrator
(DBA) is the person or group in charge for implementing the database system
,within an organization. The "DBA has all the system privileges allowed by
the DBMS and can assign (grant) and remove (revoke) levels of access (privileges)
to and from other users. DBA is also responsible for the evaluation, selection
and implementation of DBMS package.
5.
Procedures:
Procedures refer to the
instructions and rules that govern the design and use of the database. The
users of the system and the staff that manage the database require documented
procedures on how to use or run the system.
These may consist of
instructions on how to:
• Log on to the DBMS.
• Use a particular DBMS
facility or application program.
• Start and stop the DBMS.
• Make backup copies of the
database.
• Handle hardware or software
failures.
Change the structure of a
table, reorganize the database across multiple disks, improve performance, or
archive data to secondary storage.
What are the Components of DBMS?
A typical structure of a DBMS with
its components and relationships between them is shown. The DBMS software is
partitioned into several modules. Each module or component is assigned a
specific operation to perform. Some of the functions of the DBMS are supported
by operating systems (OS) to provide basic services and DBMS is built on top of
it. The physical data and system catalog are stored on a physical disk. Access
to the disk is controlled primarily by as, which schedules disk input/output.
Therefore, while designing a DBMS its interface with the as must be taken into
account.
Components of a DBMS
The DBMS accepts the SQL
commands generated from a variety of user interfaces, produces query evaluation
plans, executes these plans against the database, and returns the answers. As
shown, the major software modules or components of DBMS are as follows:
(i)
Query processor:
The query processor transforms user queries
into a series of low level instructions. It is used to interpret the online
user's query and convert it into an efficient series of operations in a form
capable of being sent to the run time data manager for execution. The query
processor uses the data dictionary to find the structure of the relevant
portion of the database and uses this information in modifying the query and preparing
and optimal plan to access the database.
(ii)
Run time database manager:
Run time database manager is
the central software component of the DBMS, which interfaces with
user-submitted application programs and queries. It handles database access at
run time. It converts operations in user's queries coming. Directly via the
query processor or indirectly via an application program from the user's
logical view to a physical file system. It accepts queries and examines the
external and conceptual schemas to determine what conceptual records are
required to satisfy the user’s request. It enforces constraints to maintain the
consistency and integrity of the data, as well as its security. It also
performs backing and recovery operations. Run time database manager is
sometimes referred to as the database control system and has the following
components:
•
Authorization control:
The authorization control
module checks the authorization of users in terms of various privileges to
users.
•
Command processor:
The command processor
processes the queries passed by authorization control module.

Integrity
checker:
It .checks the integrity
constraints so that only valid data can be entered into the database.
Query
optimizer:
The query optimizers
determine an optimal strategy for the query execution.
•
Transaction manager:
The transaction manager
ensures that the transaction properties
should be maintained by the system.
•
Scheduler:
It provides an environment in
which multiple users can work on same piece of data at the same time in other
words it supports concurrency.
(iii)
Data Manager:
The data manager is
responsible for the actual handling of data in the database. It provides
recovery to the system which that system should be able to recover the data
after some failure. It includes Recovery manager and Buffer manager. The buffer
manager is responsible for the transfer of data between the main memory and secondary storage (such as disk or
tape). It is also referred as the cache manger.
Execution Process of a DBMS
As show, conceptually,
following logical steps are followed while executing users to request to access
the database system:
(I) Users issue a query using
particular database language, for example, SQL commands.
(ii) The passes query is presented to a query
optimizer, which uses information about how the data is stored to produce an
efficient execution plan for the evaluating the query.
(iii) The DBMS accepts the users SQL commands and
analyses them.
(iv) The DBMS produces query evaluation plans, that
is, the external schema for the user, the corresponding external/conceptual
mapping, the conceptual schema, the conceptual/internal mapping, and the
storage structure definition. Thus, an evaluation\ plan is a blueprint for
evaluating a query.
(v) The DBMS executes these plans against the
physical database and returns the answers to the user.
Using components such as
transaction manager, buffer manager, and recovery manager, the DBMS supports
concurrency and recovery.
Advantages of DBMS
The database management
system has promising potential advantages, which are explained below:
1.
Controlling Redundancy:
In file system, each
application has its own private files, which cannot be shared between multiple
applications. 1:his can often lead to considerable redundancy in the stored
data, which results in wastage of storage space. By having centralized database
most of this can be avoided. It is not possible that all redundancy should be
eliminated. Sometimes there are sound business and technical reasons for·
maintaining multiple copies of the same data. In a database system, however
this redundancy can be controlled.
For example: In case of college database, there may be the number of
applications like General Office, Library, Account Office, Hostel etc. Each of
these applications may maintain the following information into own private file
applications:

It is clear from the above
file systems, that there is some common data of the student which has to be
mentioned in each application, like Rollno, Name, Class, Phone_No~ Address etc.
This will cause the problem of redundancy which results in wastage of storage
space and difficult to maintain, but in case of centralized database, data can
be shared by number of applications and the whole college can maintain its
computerized data with the following database:

It is clear in the above
database that Rollno, Name, Class, Father_Name, Address,
Phone_No, Date_of_birth which
are stored repeatedly in file system in each application, need not be stored
repeatedly in case of database, because every other application can access this
information by joining of relations on the basis of common column i.e. Rollno.
Suppose any user of Library system need the Name, Address of any particular
student and by joining of Library and General Office relations on the basis of
column Rollno he/she can easily retrieve this information.
Thus, we can say that
centralized system of DBMS reduces the redundancy of data to great extent but
cannot eliminate the redundancy because RollNo is still repeated in all the
relations.
1.
Integrity can be enforced:
Integrity of data means that
data in database is always accurate, such that incorrect information cannot be
stored in database. In order to maintain the integrity of data, some integrity
constraints are enforced on the database. A DBMS should provide capabilities
for defining and enforcing the constraints.
For Example: Let us consider
the case of college database and suppose that college having only BTech, MTech,
MSc, BCA, BBA and BCOM classes. But if a user enters the class MCA, then this
incorrect information must not be stored in database and must be prompted that
this is an invalid data entry. In order to enforce this, the integrity
constraint must be applied to the class attribute of the student entity. But,
in case of file system tins constraint must be enforced on all the application
separately (because all applications have a class field).
In case of DBMS, this
integrity constraint is applied only once on the class field of the
General Office (because class
field appears only once in the whole database), and all other applications will
get the class information about the student from the General Office table so
the integrity constraint is applied to the whole database. So, we can conclude
that integrity constraint can be easily enforced in centralized DBMS system as
compared to file system.
3. Inconsistency can be avoided :
When the same data is
duplicated and changes are made at one site, which is not propagated to the
other site, it gives rise to inconsistency and the two entries regarding the
same data will not agree. At such times the data is said to be inconsistent.
So, if the redundancy is removed chances of having inconsistent data is also
removed.
4. Data can be shared:
As explained earlier, the
data about Name, Class, Father __name etc. of General Office is shared by
multiple applications in centralized DBMS as compared to file system so now
applications can be developed to operate against the same stored data. The
applications may be developed without having to create any new stored files.
5.
Standards can be enforced :
Since DBMS is a central
system, so standard can be enforced easily may be at Company level, Department
level, National level or International level. The standardized data is very
helpful during migration or interchanging of data. The file system is an
independent system so standard cannot be easily enforced on multiple
independent applications.
6. Restricting unauthorized access:
When multiple users share a
database, it is likely that some users will not be authorized to access all
information in the database. For example, account office data is often
considered confidential, and hence only authorized persons are allowed to
access such data. In addition, some users may be permitted only to retrieve data,
whereas other are allowed both to retrieve and to update. Hence, the type of
access operation retrieval or update must also be controlled. Typically, users
or user groups are given account numbers protected by passwords, which they can
use to gain access to the database. A DBMS should provide a security and
authorization subsystem, which the DBA uses to create accounts and to specify
account restrictions. The DBMS should then enforce these restrictions
automatically.
7. Solving Enterprise Requirement than Individual
Requirement:
Since many types of users
with varying level of technical knowledge use a database, a DBMS should provide
a variety of user interface. The overall requirements of the enterprise are
more important than the individual user requirements. So, the DBA can structure
the database system to provide an overall service that is "best for the
enterprise".
For example: A representation
can be chosen for the data in storage that gives fast access for the most
important application at the cost of poor performance in some other
application. But, the file system favors the individual requirements than the
enterprise requirements
A DBMS must provide
facilities for recovering from hardware or software failures. The backup and
recovery subsystem of the DBMS is responsible for recovery. For example, if the
computer system fails in the middle of a complex update program, the recovery
subsystem is responsible for making sure that the .database is restored to the
state it was in before the program started executing.
9. Cost of developing and maintaining system is lower:
It is much easier to respond
to unanticipated requests when data is centralized in a database than when it
is stored in a conventional file system. Although the initial cost of setting
up of a database can be large, but the cost of developing and maintaining
application programs to be far lower than for similar service using
conventional systems. The productivity of programmers can be higher in using
non-procedural languages that have been developed with DBMS than using
procedural languages.
10.
Data Model can be developed :
The centralized system is
able to represent the complex data and interfile relationships, which results
better data modeling properties. The data madding properties of relational
model is based on Entity and their Relationship, which is discussed in detail
in chapter 4 of the book.
11.
Concurrency Control :
DBMS systems provide
mechanisms to provide concurrent access of data to multiple users.
Disadvantages of DBMS
The disadvantages of the
database approach are summarized as follows:
1. Complexity :
The provision of the
functionality that is expected of a good DBMS makes the DBMS an extremely
complex piece of software. Database designers, developers, database
administrators and end-users must understand this functionality to take full
advantage of it. Failure to understand the system can lead to bad design
decisions, which can have serious consequences for an organization.
2. Size :
The complexity and breadth of
functionality makes the DBMS an extremely large piece of software, occupying
many megabytes of disk space and requiring substantial amounts of memory to run efficiently.
3. Performance:
Typically, a File Based
system is written for a specific application, such as invoicing. As result,
performance is generally very good. However, the DBMS is written to be more
general, to cater for many applications rather than just one. The effect is
that some applications may not run as fast as they used to.
4.Higher impact of a failure:
The centralization of
resources increases the vulnerability of the system. Since all users and
applications rely on the ~vailabi1ity of the DBMS, the failure of any component
can bring operations to a halt.
5. Cost of DBMS:
The cost of DBMS varies
significantly, depending on the environment and functionality provided. There
is also the recurrent annual maintenance cost.
Additional Hardware costs:
The disk storage requirements for the DBMS and the database may
necessitate the purchase of additional storage space. Furthermore, to achieve
the required performance it may be necessary to purchase a larger machine,
perhaps even a machine dedicated to running the DBMS. The procurement of
additional hardware results in further expenditure.
7. Cost of Conversion:
In some situations, the cost
oftlle DBMS and extra hardware may be insignificant compared with the cost of
converting existing applications to run on the new DBMS and hardware. This cost
also includes the cost of training staff to use these new systems and possibly
the employment of specialist staff to help with conversion and running of the
system. This cost is one of the main reasons why some organizations feel tied
to their current systems and cannot switch to modern database technology.
The DBMS can
be classified according to the number of users and the database site locations. These are:
On the basis of the number of
users:
• Single-user DBMS
• Multi-user DBMS
On the basis of the site
location
• Centralized DBMS
• Parallel DBMS
• Distributed DBMS
• Client/server DBMS
we will discuss about some of
the important types of DBMS system, which are presently being used.
The database system may be
multi-user or single-user. The configuration of the hardware and the size of
the organization will determine whether it is a multi-user system or a single
user system.
In single user system the
database resides on one computer and is only accessed by one user at a
time. This one user may design, maintain, and write database programs.
Due to large amount of data
management most systems are multi-user. In this situation the data are both
integrated and shared. A database is integrated when the same information is not recorded in two places. For
example, both the Library department and the Account department of the college
database may need student addresses. Even though both departments may access
different portions of the database, the students' addresses should only reside
in one place. It is the job of the DBA to make sure that the DBMS makes the
correct addresses available from one central storage area.
Centralized Database System
The centralized database
system consists of a single processor together with its associated data storage devices and other peripherals. It is physically
confined to a single location. Data can be accessed from the multiple sites
with the use of a computer network while the database is maintained at the
central site.

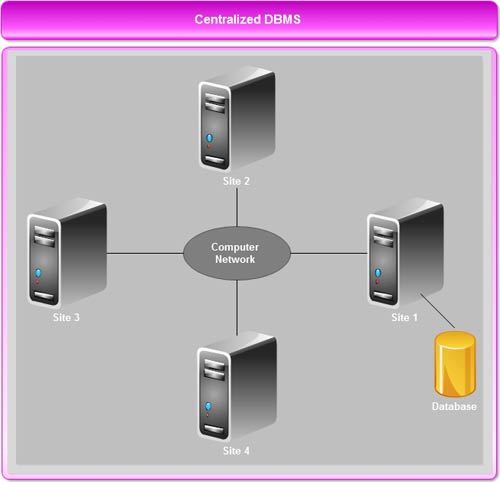{kind=link}
Disadvantages of Centralized
Database System
• When the central site
computer or database system goes down, then every one (users) is blocked from
using the system until the system comes back.
• Communication costs from
the terminals to the central site can be expensive.
Parallel Database System
Parallel database system
architecture consists of a multiple Central
Processing Units (CPUs) and data
storage disk in parallel. Hence, they improve processing and Input/Output (I/O)
speeds. Parallel database systems are used in the application that have to
query extremely large databases or that have to process an extremely large
number of transactions per second.
Advantages of a Parallel
Database System
• Parallel database systems
are very useful for the applications that have to query extremely large
databases (of the order of terabytes, for example, 1012 bytes) or that have to
process an extremely large number of transactions per second (of the order of
thousands of transactions per second).
• In a parallel database
system, the throughput (that is, the number of tasks that can be completed in a
given time interval) and the response time (that is, the amount of time it
takes to complete a single task from the time it is· submitted) are very high.
Disadvantages of a Parallel
Database System
• In a parallel database
system, there· is a startup cost associated with initiating a single process
and the startup-time may overshadow the actual processing time, affecting
speedup adversely.
• Since process executing in
a parallel system often access shared resources, a slowdown may result from
interference of each new process as it completes with existing processes for
commonly held resources, such as shared data storage disks, system bus and so
on.
Distributed Database System
A logically interrelated
collection of shared data physically distributed over a computer network is
called as distributed database and the software system that permits the
management of the distributed database and makes the distribution transparent
to users is called as Distributed DBMS.
It consists of a single
logical database that is split into a number of fragments. Each fragment is
stored on one or more computers under the control of a separate DBMS, with the
computers connected by a communications network. As shown, in distributed database
system, data is spread across a variety of different databases. These are
managed by a variety of different DBMS software running on a variety of
different operating systems. These machines are spread (or distributed)
geographically and connected together by a variety of communication networks.

Advantages of Distributed
Database System
• Distributed database
architecture provides greater efficiency and better performance.
• A single database (on
server) can be shared across several distinct client (application) systems.
• As data volumes and
transaction rates increase, users can grow the system incrementally.
• It causes less impact on
ongoing operations when adding new locations.
• Distributed database system
provides local autonomy.
Disadvantages of Distributed
Database System
• Recovery from failure is
more complex in distributed database systems than in centralized systems.
Client-Server DBMS
Client/Server architecture of
database system has two logical components namely client, and server. Clients
are generally personal computers or workstations whereas server is large
workstations, mini range computer system or a mainframe computer system. The
applications and tools of DBMS run on one or more client platforms, while the
DBMS soft wares reside on the server. The server computer is caned backend and
the client's computer is called front end. These server and client computers
are connected into a network. The applications and tools act as clients of the
DBMS, making requests for its services. The DBMS, in turn, processes these
requests and returns the results to the client(s). Client/Server architecture
handles the Graphical User Interface (GUI) and does computations and other
programming of interest to the end user. The server handles parts of the job
that are common to many clients, for example, database access and updates.
Multi-Tier client server
computing models
In a single-tier system the
database is centralized, which means the DBMS Software and the data reside in
one location and the dumb terminals were used to access the DBMS as shown.

The rise of personal
computers in businesses during the 1980s, the increased reliability of
networking hardware causes Two-tier and Three-tier systems became common. In a
two-tier system, different software is required for the server and for the
client. Illustrates the two-tier client server model. At the early stages
client server computing model was called two-tier-computing model in which
client is considered as data capture and validation tier and Server was
considered as data storage tier. This scenario is depicted.
Problems of two-tier
architecture
The need of enterprise
scalability challenged this traditional two-tier client-server model. In the mid-1990s, as
application became more complex and could be deployed to hundreds or thousands of end-users, the
client side, now undergoes with following problems:

• A' fat' client requiring
considerable resources on client's computer to run effectively. This includes
disk space, RAM and CPU.
• Client machines require
administration which results overhead.
Three-tier architecture
By 1995, three-tier
architecture appears as improvement over two-tier architecture. It has three
layers, which are:
• First Layer: User Interface which runs on end-user's computer (the client) .
• Second Layer: Application Server It is a business logic and data processing
layer. This middle tier runs on a server which is called as Application Server.
• Third Layer: Database Server It is a
DBMS, which stores the data required by the middle tier. This tier may run on a
separate server called the database server.
As, described earlier, the
client is now responsible for application's user interface, thus it requires
less computational resources now clients are called as 'thin client' and it
requires less maintenance.
Advantages of Client/Server
Database System
• Client/Server system has
less expensive platforms to support applications that had previously been
running only on large and expensive mini or mainframe computers
• Client offer icon-based
menu-driven interface, which is superior to the traditional command-line, dumb
terminal interface typical of mini and mainframe computer systems.
• Client/Server environment
facilitates in more productive work by the users and making better use of
existing data.

• Client/Server database
system is more flexible as compared to the Centralized system.
• Response time and
throughput is high.
• The server (database)
machine can be custom-built (tailored) to the DBMS function and thus can
provide a better DBMS performance.
• The client (application database)
might be a personnel workstation, tailored to the needs of the end users and
thus able to provide better interfaces, high availability, faster responses and
overall improved ease of use to the user. + A single database (on server) can
be shared across several distinct client (application) systems.
Disadvantages of
Client/Server Database System
• Programming cost is high in
client/server environments, particularly in initial phases.
• There is a lack of
management tools for diagnosis, performance monitoring and tuning and security
control, for the DBMS, client and operating systems and networking
environments.
What is Data Independence?
Data independence is the
type of data transparency
that matters for a centralized DBMS. It refers to the immunity of
user applications to changes made in the
definition and organization of data.
There are two kinds of data
independence:
• Logical data
independence
• Physical data independence
Logical Data Independence
Logical data independence
indicates that the conceptual schema can be changed without affecting the
existing external schemas. The change would be absorbed by the mapping between
the external and conceptual levels. Logical data independence also insulates
application programs from operations such as combining two records into one or
splitting an existing record into two or more records. This would require a.
change in the external/conceptual mapping so as to leave the external view
unchanged.
Physical Data Independence
Physical data independence
indicates that the physical storage structures or devices could be changed
without affecting conceptual schema. The change would be absorbed by the
mapping between the conceptual and internal levels. Physic 1data independence
is achieved by the presence of the internal level of the database and the n, lapping
or transformation from the conceptual level of the database to the internal
level. Conceptual level to internal level mapping, therefore provides a means
to go from the conceptual view (conceptual records) to the internal view and
hence to the stored data in the database (physical records).
If there is a need to change
the file organization or the type of physical device used as a result of growth
in the database or new technology, a change is required in the conceptual/
internal mapping between the conceptual and internal levels. This change is
necessary to maintain the conceptual level invariant. The physical data
independence criterion requires that the conceptual level does not specify
storage structures or the access methods (indexing, hashing etc.) used to
retrieve the data from the physical storage medium. Making the conceptual
schema physically data independent means that the external schema, which is
defined on the conceptual schema, is in turn physically data independent.
The Logical data independence
is difficult to achieve than physical data independence as it requires the
flexibility in the design of database and prograll1iller has to foresee the
future requirements or modifications in the design.
What is a Database
Architecture
An early proposal for a
standard terminology and general architecture for database systems was produced
in 1971 by the DBTG (Data Base Task Group) appointed by the Conference on Data
Systems and Languages (CODASYL, 1971). The DBTG recognized the need for a two
level approach with a system view called the schema and user views called
subschema. The American National Standards Institute (ANSI) Standards Planning
and Requirements Committee (SPARC) produced a similar terminology mid architecture
in 1975 (ANSI 1975). ANSI-SPARC recognized the need for a three level approach
with a system catalog.
There are following
three levels or layers of DBMS
architecture:
• External Level
•Conceptual Level
• Internal Level
Objective of the Three Level
Architecture
The objective of the three
level architecture is to separate each user's view of the database from the Way
the database is physically represented. There are several reasons why this
separation is desirable:
• Each user should be able to
access the same data, but have a different customized view of the data. Each
user should be able to change the way he or she views the data, and this change
should not affect other users.
• Users should not have to
deal directly with physical database storage details, such as indexing or
hashing. In other words a user's interaction with the database should be
independent of storage considerations.
• The Database Administrator
(DBA) should be able to change the database storage structures without
affecting the user's views.
. The internal structure of
the database should be unaffected by changes to the physical aspects of
storage, such as the changeover to a new storage device.
. The DBA should be able to
change the conceptual structure of the database without affecting all users.
External Level or View level
It is the users' view of the
database. This level describes that part of the database that is relevant to
each user. External level is the one which is closest to the end users. This
level deals with the way in which individual users vie\v data. Individual users
are given different views according to the user's requirement.
A view involves only those
portions of a database which are of concern to a user. Therefore same database
can have different views for different users. The external view insulates users
from the details of the internal and conceptual levels. External level is also
known as the view level. In addition different views may have different
representations of the same data. For example, one user may view dates in the
form (day, month, year), while another may view dates as (year, month, day).
Conceptual Level or Logical
level
It is the community view of
the database. This level describes what data is stored in the database and the
relationships among the data. The middle level in the three level architecture
is the conceptual level. This level contains the logical structure of the
entire database as seen by the DBA. It is a complete view of the data
requirements of the organization that is independent of any storage
considerations. The conceptual level represents:
• All entities, their
attributes, and their relationships;
An Entity is an object whose information is stored in the database. For
example, in student database the entity is student. An attribute is a
characteristic of interest about an entity.
For example, in case of
student database Roll No, Name, Class, Address etc. are attributes of entity
student.

• The constraints on the
data;
• Semantic information about
the data;
• Security and integrity
information.
The conceptual level supports
each external view, in that any data available to a user must be contained in,
or derivable from, the conceptual level. However, this level must not contain
any storage dependent details. For instance, the description of an entity
should contain only data types of
attributes (for example, integer, real, character) and their length (such as
the maximum number of digits or characters), but not any storage
considerations, such as the number of bytes occupied. Conceptual level is also
known as the, logical level.
Internal level or Storage
level
It is the physical
representation of the database on the computer.
This level describes how the data is stored in the database. The internal level
is the one that concerns the way the data are physically stored on the
hardware. The internal level covers the physical\ implementation of the
database to achieve optimal runtime performance and storage space utilization.
It covers the data structures and file organizations used to store data on storage devices. It interfaces with
the operating system access
methods to place the data on the storage devices, build the indexes, retrieve
the data, and so· on.
The internal level is
concerned with such things as:
• Storage space allocation
for data and indexes;
• Record descriptions for
storage (with stored sizes for data items);
• Record placement;
• Data compression and data
encryption techniques.
There will be only one
conceptual view, consisting of the abstract representation of the database in
it’s entirely. Similarly there will be only one internal or physical view,
representing the total database, as it is physically stored.
What is Schema?
It is important to note that
the data in the database changes frequently, while the plans or schemes remain
the same over long periods of time. The database plans consist of types of
entities that a database deals with, the relationship among these entities and
the ways in which the entities and relationships are expressed from one level
of abstraction to the next level for the users' view. The users' view of the
data (also called logical organization of data) should be in a form that is
most convenient for the users and they should not be concerned about the way
data is physically organized. Therefore, a DBMS should do the translation
between the logical (users' view) organization and the physical organization of
the data in the database.
The plan or scheme of the
database is known as Schema. Schema gives the names of the entities and
attributes. It specifies the relationship among them. It is a framework into
which the values of the data items (or fields) are fitted. The plans or the
format of schema remains the same. But the values fitted into this format
changes from instance to instance. In other terms, schema means overall plans
of all the data item (field) types and record types stored in a database.
Schema includes the definition of the database name, the record type and the
components that make up those records
Types of Schema
There are three different
types of schema in the database corresponding to each data view of database. In
other words, the data views at each of three levels are described by schema.
A schema is defined as an
outline or a plan that describes the records and relationships existing at the
particular level. The External view is described by means of a schema called
external schema that correspond to different views of the data. Similarly the
Conceptual view is defined by conceptual schema, which describes all the
entities, attributes, and relationship together with integrity constraints.
Internal View is defined by internal schema, which is a complete description of
the internal model, containing definition of stored records, the methods of
representation, the data fields, and the indexes used.
There is only one conceptual
schema and one internal schema per database. The schema also describes the way
in which data elements at one level can be mapped to the corresponding data
elements in the next level.
Thus, we can say that schema
establishes correspondence between the records and relationships in the two
levels. In a relational database, the schema defines the tables, the fields in
each table, and the relationships between fields and tables. Schema are
generally stored in a data dictionary.
The data in the database at
any particular point in time is called a database instance. Therefore, many
database instances can correspond to the same database schema. The schema is
sometimes called the intension of the database, while an instance is called an
extension (or state) of the database.

Example: To understand the
difference between the three levels, consider again the database schema that
describes College Database system. If User1 is a Library clerk, the external
view would contain only the student and book information. If User2 is an
account office clerk then he/she may be interested in students detail and fee
detail. Shows specific information actually available at each level regarding a
particular user.
The external view would
depend upon the user who is accessing the database. The conceptual level
contain the logical view of the whole database, it represents the data type of
each required field. The internal view represents the physical location of each
element on the disk of the servers well as how many bytes of storage each
element needs.
Mapping between Views
The DBMS is responsible for
mapping between these three types of schema. Two mappings are required in a
database system with three different views.
External/Conceptual Mapping:
Each external schema is
related to the conceptual schema by the external/conceptual mapping. A mapping
between the external and conceptual views gives the correspondence among the
records and the relationships of the external and conceptual views the external
view is an abstraction of the conceptual view, which in its turn is an
abstraction of the internal view. It describes the contents of the database as
perceived by the user or application program of that view. The user of the
external view sees and manipulates a record corresponding to the external view.
There is a mapping from0 a particular logical record in the external view to
one (or more) conceptual record(s) in the conceptual view.
Differences between
External/Conceptual views
Following could be
differences that exist between the two:
Names of the field’s and.
records, for instance, may be different. A number of conceptual fields can be
combined into a single external field, for example, Last_Name and First_Name at
the conceptual level but Name at the external level. A given external record
could be derived from a number of conceptual .records.
Conceptual/Internal Mapping:
Conceptual schema is related to the internal schema by the
conceptual/internal mapping. This enables the DBMS to find the actual record or
combination of records in physical storage that constitute a logical record in
conceptual schema. Mapping between the conceptual and the internal levels
specifies the method of deriving the conceptual record from the physical
database.

What is Mapping?
We
know that three view-levels are described by means of three schemas. These
schemas are stored in the data dictionary. In DBMS, each user refers
only to its own external schema. Hence, the DBMS
must transform a request on. A specified external schema
into a request against conceptual schema, and then into a request against
internal schema to store and retrieve data to and from the database.
The process to convert a request (from external level) and the
result between view levels is called mapping. The mapping defines the
correspondence between three view levels. The mapping description is also
stored in data dictionary. The DBMS is responsible for mapping between these
three types of schemas. There are two types of mapping.
(i)
External-Conceptual mapping
An external-conceptual mapping
defines the correspondence between a particular external view and
the conceptual view. The external-conceptual mapping tells
the DBMS which objects on the conceptual level correspond to the
objects requested on a particular user's external view. If changes
are made to either an external view or conceptual view,
then mapping must be changed accordingly.
(ii)
Conceptual-Internal
mapping
The conceptual-internal
mapping defines the correspondence between the conceptual view and
the internal view, i.e. Database stored on the physical storage device. It
describes how conceptual records are stored and retrieved to and from
the storage device. This means that conceptual-internal mapping tells the
DBMS that how the conceptual! Records are physically represented. If the
structure of the stored database is changed, then the mapping must be changed accordingly.
It is the responsibility of DBA to manage such changes.
What is Database
Administration?
Database
administration is the function of managing and maintaining database
management systems (DBMS) software. Mainstream DBMS software such as Oracle,
IBM DB2 and Microsoft SQL Server need ongoing management.
Who is DBA? What are the Role
and Responsibilities of DBA?
Database Administrator (DBA)
is a person or group in charge for implementing DBMS in
an organization. Database Administrator's job requires a high degree of
technical expertise and the ability to understand and interpret management
requirements at a senior level. In practice the DBA may consist of team of
people rather than just one person
The main responsibilities of
DBA are:
• Makes decisions
concerning the content of the database:
It is the DBA's job to decide exactly what information is to be held in the database-in other
words, to identify the' entities of interest to the enterprise and to identify
information to be recorded about those entities .
• Plans storage
structures and access strategies:
The DBA must also decide how the data is to be
represented in the database, and must specify the representation by writing the
storage structure definition (using the internal data definition language).
In addition, the associated
mapping between the storage structure definition and the conceptual schema must
also be specified.
• Provides support to
users:
It is the responsibility of
the DBA to provide support to the users, to ensure that the data they require
is available, and to write the\ necessary external schemas (using the
appropriate external data definition language).
In addition, the mapping
between any given eA1ernal schema and the conceptual' schema must also be
specified.
• Defines security and
integrity checks:
DBA is responsible for
providing the authorization and authentication checks such that no malicious
users can access database and it must remain protected. DBA must also ensure
the integrity of the database.
• Interprets backup and
recovery strategies:
In the event of damage to any
portion\ of the database-caused by human error, say, or a failure in the
hardware or supporting operating system-it is essential to be able to repair
the data concerned witl1 a minimum of delay and with as little effect as
possible on the rest of the system.
The DBA must define and
implement an appropriate recovery strategy to recover he database from all
types of failures.
• Monitoring
performance and responding to changes in requirements:
The DBA is responsible for so
organizing the system as to get the performance that is "best for the
enterprise," and for making the appropriate adjustments as requirements
change.
The DBA should posses the
following skills
(1) A good knowledge of the operating system(s)
(2) A good knowledge of
physical database design
(3) Ability to perform both
Oracle and also operating system performance monitoring and the necessary
adjustments.
(4) Be able to provide a
strategic database direction for the organization.
(5) Excellent knowledge of
Oracle backup and recovery scenarios.
(6) Good skills in all Oracle
tools.
(7) A good knowledge of
Oracle security management.
(8) A good knowledge of how
Oracle acquires and manages resources.
(9) Sound knowledge of the
applications at your site.
(10) Experience and knowledge
in migrating code, database changes, data and
Menus through the various stages
of the development life cycle.
(11) A good knowledge of the
way Oracle enforces data integrity.
(12) A sound knowledge of
both database and program code performance tuning.
(13) A DBA should possess a
sound understanding of the business.
(14) A DBA should have sound
communication skills with management, development teams, vendors, systems
administrators and other related service providers.
What is Data Manager?
The data manager is the
central software component of the DBMS. It is sometimes referred to as the
database control system. One of the functions of the data manager is to convert
operations in the user's queries coming directly via the query processor or\
indirectly via an application program from the user's logical view to a
physical file system. The data manager is responsible for interfacing with the
file system as show. In addition, the tasks of enforcing constraints to
maintain the consistency and integrity of the data, as well as its security,
are also performed by the data manager. It is also the responsibility of the
Data. Manager to provide the synchronization in the simultaneous operations
performed by concurrent users and to maintain the backup and recovery
operations.
What is File Manager?
Responsibility for the
structure of the files and managing the file space rests with the file manager.
It is also responsible for locating the block containing the required record,
requesting this block from the disk manager, and transmitting the required
record to the data manager as shown. The file manager can be implemented using
an interface to the existing file subsystem provided by the operating system of the host computer or it can include a file subsystem
written especially for the DBMS.
What is Disk Manager?
The disk manager is part of
the operating system of the host computer and all physical input and output
operations are performed by it. The disk manager transfers the block or page
requested by the file manager so that the latter need not be concerned with the
physical characteristics of the underlying storage media.
What are Data Models? Type of
Data Models.
Data Model can be defined as
an integrated collection of concepts for describing and manipulating data,
relationships between data, and constraints on the data in an organization.
A data model comprises of
three components:
i.
A structural part, consisting of a set of rules according to which
databases can be constructed.
ii.
A manipulative part, defining the types of operation that are
allowed on the data (this includes the operations that are used for updating or
retrieving data from the database and for changing the structure of the
database).
iii.
Possibly a set of integrity rules, which ensures that the data is
accurate.
The purpose of a data model
is to represent data and to make the data understandable. There have been many
data models proposed in the literature. They fall into three broad categories:
·
Object Based Data Models
·
Physical Data Models
·
Record Based Data Models
The object based and record
based data models are used to describe data at the conceptual and external
levels, the physical data model is used to· describe data at the internal
level.
Object Based Data Models
Object based data models use
concepts such as entities, attributes, and relationships. An entity is a
distinct object (a person, place, concept, and event) in the organization that
is to be represented in the database. An attribute is a property that describes
some aspect of the object that we wish to record, and a relationship is an
association between entities.
Some of the more common types
of object based data model are:
• Entity-Relationship
• Object Oriented
• Semantic
• Functional
The Entity-Relationship
model has emerged as one of the main techniques for modeling database design
and forms the basis for the database design methodology. The object oriented
data model extends the definition of an entity to include, not only the
attributes that describe the state of the object but also the actions that are
associated with the object, that is, its behavior. The object is said to
encapsulate both state and behavior. Entities in semantic systems represent the
equivalent of a record in a relational system or an object in an OO system but
they do not include behavior (methods). They are abstractions 'used to
represent real world (e.g. customer) or conceptual (e.g. bank account) objects.
The functional data model is now almost twenty years old. The original idea was
to' view the database as a collection of extensionally defined functions and to
use a functional language for querying the database.
Physical Data Models
Physical data models describe
how data is stored in the computer,
representing information such as record structures, record
ordering, and access paths. There are not as many physical data models as
logical data models, the most common one being the Unifying Model.
Record Based Logical Models
Record based logical models
are used in describing data at the logical and view levels. In contrast to
object based data models, they are used to specify the overall logical structure
of the database and to provide a higher-level description of the
implementation. Record based models are so named because the database is
structured in fixed format records of several types. Each record type defines a
fixed number of fields, or attributes, and each field is usually of a fixed
length.
The three most widely
accepted record based data models are:
• Hierarchical Model
• Network Model
• Relational Model
The relational model has
gained favor over the other two in recent years. The network and hierarchical
models are still used in a large number of older databases.
What is ER-Model? Advantages
and Disadvantages of E-R Model.
There are two techniques used
for the purpose of data base designing from the system requirements. These are:
• Top down Approach
known as Entity-Relationship Modeling
• Bottom Up approach known as
Normalization.
we will focus on top
down approach of designing database. It is a graphical technique, which is used
to convert the requirement of the system to graphical representation, so that
it can become well understandable. It also provides the framework for designing
of database.
The Entity-Relationship (ER)
model was originally proposed by Peter in 1976 as a way to unify the network
and relational database views. Simply stated, the ER model is a conceptual data
model that views the real world as entities and relationships. A basic
component of the model is the Entity-Relationship diagram, which is used to
visually represent data objects. For the database designer, the utility of the
ER model is:
• It maps well to the
relational model. The constructs used in the ER model can easily be transformed
into relational tables.
• It is simple and easy to
understand with a minimum of training. Therefore, the model can be used by the
database designer to communicate the design to the end user.
• In addition, the model can
be used as a design plan by the database developer to implement a data model in
specific database management software.
Advantages and Disadvantages of E-R Data Model
Following are advantages of
an E-R Model:
• Straightforward relation
representation: Having designed an E-R
diagram for a database application, the relational representation of the
database model becomes relatively straightforward.
• Easy conversion for E-R to
other data model: Conversion from E-R diagram
to a network or hierarchical data model can· easily be accomplished.
• Graphical representation
for better understanding: An E-R model gives graphical and diagrammatical
representation of various entities, its attributes and relationships between
entities. This is turn helps in the clear understanding of the data structure
and in minimizing redundancy and other problems.
Disadvantages of E-R Data Model
Following are disadvantages
of an E-R Model:
• No industry standard for
notation: There is no industry standard notation for
developing an E-R diagram.
• Popular for high-level
design: The
E-R data model is especially popular for high level.
What is Metadata OR Data
Dictionary?
A metadata (also called the data dictionary) is the data
about the data. It is the self describing nature of the database that provides
program-data independence. It is also called as the System Catalog. It holds
the following information about each data element in the
databases, it normally includes:
+ Name
+ Type
+ Range of values
+ Source
+ Access authorization
+ Indicates which application
programs use the data so that, when a change in a data structure is
contemplated, a list of the affected programs can be generated.
Data dictionary is used to
actually control the database operation, data integrity and accuracy. Metadata
is used by developers to develop the programs, queries, controls and procedures
to manage and manipulate the data. Metadata is available to database administrators
(DBAs), designers and authorized user as on-line system documentation. This
improves the control of database administrators (DBAs) over the information
system and the user's understanding and use of the system.
Active and Passive Data
Dictionaries
Data dictionary may be either
active or passive. An active data dictionary (also called integrated data
dictionary) is managed automatically by the database management software.
Consistent with the current structure and definition of the database. Most of
the relational database management systems contain active data dictionaries
that can be derived from their system catalog.
The passive data dictionary
(also called non-integrated data dictionary) is the one used only for
documentation purposes. Data about fields, files, people and so on, in the data
processing environment are. Entered into the dictionary and cross-referenced.
Passive dictionary is simply a self-contained application. It is managed by the
users of the system and is modified whenever the structure of the database is
changed. Since this modification must be performed manually by the user, it is
possible that the data dictionary will not be current with the current
structure of the database. However, the passive data dictionaries may be maintained
as a separate database. Thus, it allows developers to remain independent from
using a particular relational database
management system. It may be extended to contain information about
organizational data that is not computerized.
Importance of Data Dictionary
Data dictionary is essential
in DBMS because of the following reasons:
• Data dictionary provides
the name of a data element, its description and data structure in which it may
be found.
• Data dictionary provides
great assistance in producing a report of where a data element is used in all
programs that mention it.
• It is also possible to
search for a data name, given keywords that describe the name. For example, one
might want to determine the name of a variable that stands for net pay. Entering
keywords would produce a list of possible identifiers and their definitions.
Using keywords one can search the dictionary to locate the proper identifier to
use in a program.
These days, commercial data
dictionary packages are available to facilitate entry, editing and to use the
data elements.
Comments
Post a Comment